

Two things are happening simultaneously across software teams right now. Some teams are shipping products that run on AI: chatbots, recommendation engines, fraud detection models, content generators. Other teams are picking up AI tools to help them test software faster, write test cases more efficiently, and analyse failures more intelligently.
These two activities look similar from the outside. Both involve AI. Both involve testing. But the discipline, the mindset, the tools, and the failure modes are completely different in each case.
Confusing them leads to real problems. A team that ships an AI-powered feature while applying only traditional automation testing methods to it will miss its most dangerous failure modes. A team that adopts AI testing tools without understanding their limits will end up with a false sense of coverage that production will eventually expose.
This blog breaks down exactly where the two disciplines diverge, what each one demands, and what it looks like when teams get it right and when they get it badly wrong, with real-world scenarios at every step.
- The Scenario That Reveals the Difference
- What Is Testing AI Systems?
- What Is Testing with AI?
- Side-by-Side Comparison: Testing AI Systems vs Testing with AI
- Why Traditional QA Methods Are Not Enough for AI Systems
- Building a QA Strategy That Covers Both
- Common Mistakes Teams Make in Each Category
- The Competitive Advantage of Getting Both Right
- How JigNect Approaches Both Disciplines
- Closing Thoughts
The Scenario That Reveals the Difference
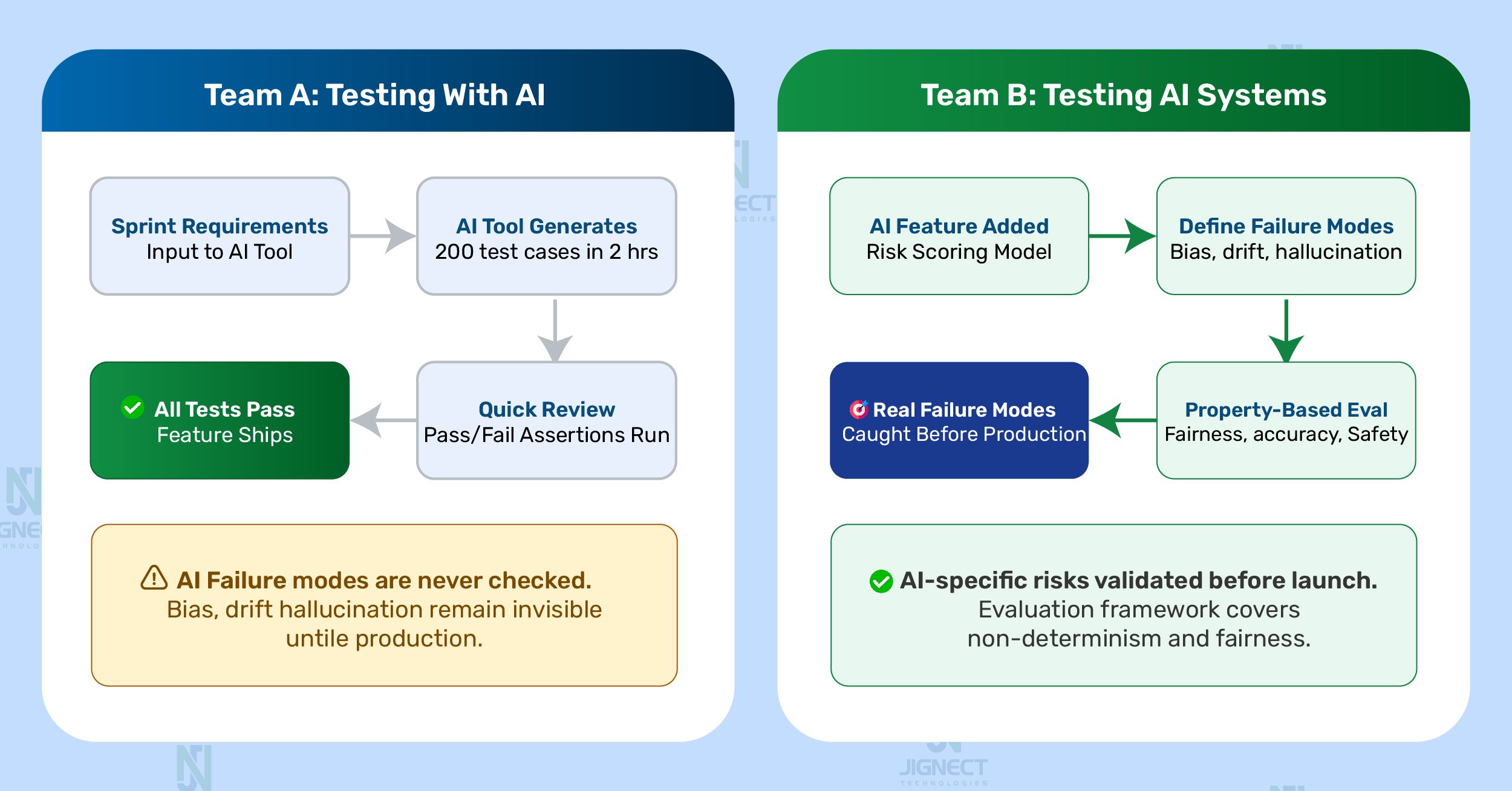
Picture two QA teams, both working on the same fintech app. The product has just added an AI-powered transaction risk scoring feature. The teams approach their work very differently.
Team A has just heard about AI tools that can generate test cases automatically. They adopt one, feed it the sprint requirements, and produce 200 test cases in an afternoon. Quick review, green pipeline, feature ships.
Team B is assigned specifically to the AI risk scoring component. They start with a different question entirely: what does it mean for an AI-powered risk model to fail? They identify failure modes that have nothing to do with whether a button works or a form submits. The model might assign high-risk scores disproportionately to transactions from certain geographies. It might produce wildly different scores for transactions that are functionally identical but phrased differently. It might degrade in accuracy over six months as fraud patterns evolve.
Team A was testing with AI. Team B was testing an AI system. Both are doing legitimate and valuable work. But they are not doing the same thing, and treating them as interchangeable is where organisations start making expensive mistakes.
This distinction becomes even more important when you read what we explored in Automation Is No Longer Enough: Welcome to AI-Driven Quality Engineering, where we outlined how the QA role is fundamentally shifting as AI enters both the products we test and the tools we test with.
What Is Testing AI Systems?
Testing AI systems means verifying that a software product whose core functionality depends on artificial intelligence or machine learning behaves correctly, safely, fairly, and reliably over time. The products this covers include chatbots, recommendation engines, fraud detection models, predictive analytics tools, AI-powered search and ranking systems, generative AI features embedded in products, computer vision systems, and natural language processing pipelines.
The defining characteristic: their behaviour is not fully determined by explicit code logic. The AI component introduces probabilistic, statistical outputs that vary based on training data, model version, input context, and sometimes subtle factors that are difficult to control or observe.
Why AI Systems Behave Differently From Traditional Software
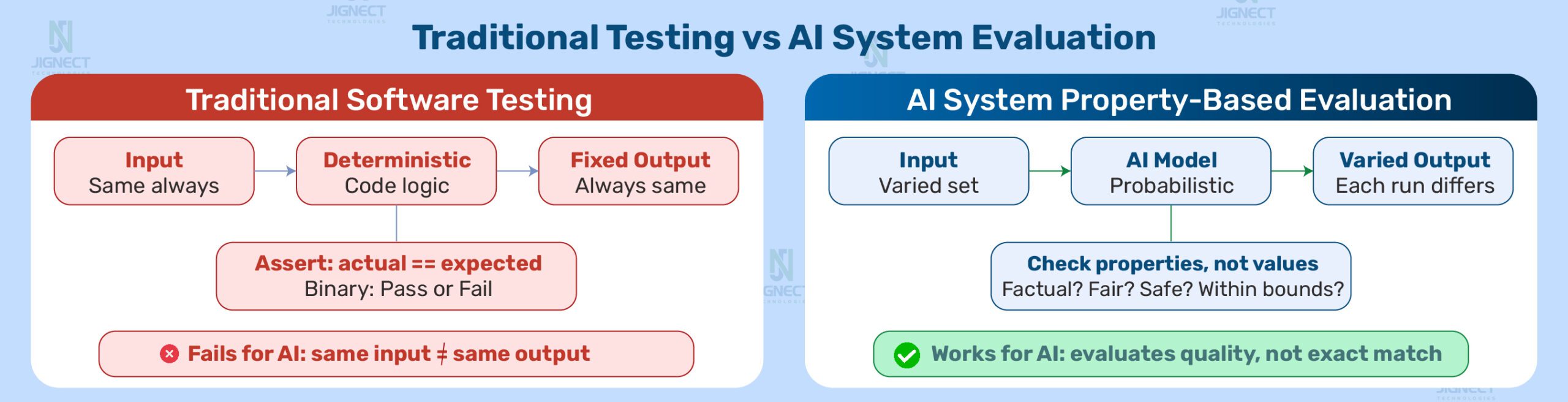
In traditional software, a function given the same inputs always produces the same output. This is the foundation of every automated regression test ever written. You capture expected outputs, run tests, compare actual to expected, and failures are clear and binary.
In an AI system, this assumption breaks down almost immediately. Ask a large language model to summarise the same document twice. The summaries will differ in phrasing or emphasis, even if both are factually correct. Ask a fraud detection model to classify the same transaction twice, with a model that has been updated between runs. The classification may differ. This is not a bug. It is the nature of probabilistic systems.
Instead of testing for exact outputs, you must test for properties of outputs: Is the output factually consistent with the source material? Does the system treat different user groups equitably? Does the model refuse harmful inputs appropriately? Does performance stay above defined thresholds as real-world data evolves?
The Core Testing Challenges Unique to AI Systems
- Non-determinism. The same input can produce different outputs across runs. Traditional regression testing will either generate false positives or miss genuine degradation.
- The oracle problem. An oracle is what tells you whether a test passed or failed. For AI systems, building a reliable oracle is one of the hardest challenges in the field. You often need a second AI model to evaluate the output of the first, which introduces its own reliability questions.
- Data dependency. The quality of an AI system cannot be separated from the quality of the training data. Testing the model without auditing the data it was trained on is like testing a car without checking the fuel.
- Temporal degradation. A fraud detection model trained on 2024 transaction patterns may become less accurate as fraud tactics shift in 2025. Testing must include ongoing monitoring and drift detection, not just pre-release validation.
- Adversarial vulnerability. AI systems, especially those processing natural language, can be deliberately manipulated. A chatbot that passes every standard test may behave very differently when someone tries to extract confidential information through carefully phrased questions.
- Fairness and bias. An AI system can produce technically accurate average results while systematically disadvantaging specific groups. Catching this requires dedicated fairness testing that goes well beyond functional validation.
These challenges are explored in depth in our post on Top 5 Challenges in AI-Based Testing: How to Overcome Them, which covers practical approaches to each.
Real-World Example: Testing a Customer Support Chatbot
A mid-sized SaaS company builds a customer support chatbot powered by a large language model. The chatbot handles account queries, billing questions, and product troubleshooting for over 50,000 active users.
The QA team approaches this with standard functional testing: they write test cases like “user asks about invoice, chatbot provides invoice details.” Every test passes. The chatbot goes live.
Within three weeks, three issues surface that the functional tests never caught: the chatbot occasionally provides billing figures that are subtly incorrect when the query uses ambiguous wording (hallucination); users trying to cancel subscriptions receive responses suggesting it is not possible, even though it is (intent misalignment from training data patterns); and accuracy drops significantly with non-native English phrasing, revealing that the training data was not representative of the actual user population.
None of these are bugs in the traditional sense. The code is working as written. The AI model is the source of all three issues, and catching them required hallucination detection, intent accuracy testing across phrasing variants, and multilingual performance benchmarking, all well beyond a functional regression suite.

What Is Testing with AI?
Testing with AI means using artificial intelligence tools to make the work of software testing faster, more thorough, or more insightful. The product being tested may have no AI in it at all. In this category, AI is the tool, not the subject of the test.
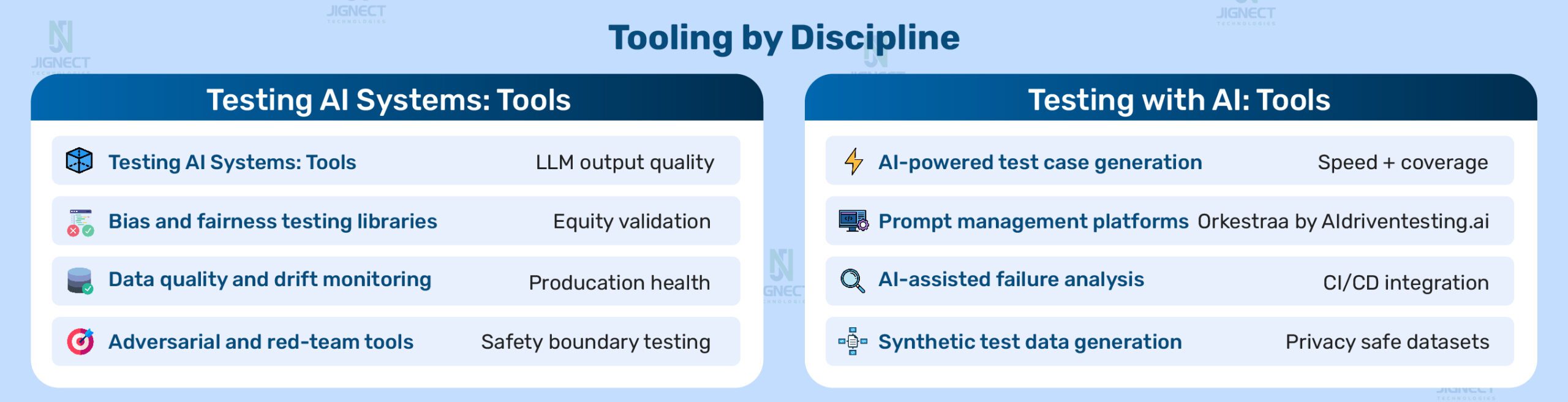
Where AI Genuinely Accelerates QA Work
- Test case generation. Writing comprehensive test cases from requirements is time-consuming. AI can generate a broad set of functional, edge case, and negative test scenarios in a fraction of the time manual writing requires, provided the prompt is well-structured and the output is reviewed with domain knowledge.
- Test data generation. Creating realistic, diverse test data at scale is tedious. AI can generate synthetic data covering edge cases, boundary conditions, and locale-specific scenarios without requiring manual creation or the use of sensitive production data.
- Failure analysis and triage. When a CI/CD pipeline produces hundreds of test failures, AI can analyse patterns, cluster related failures, and surface the most likely root causes, dramatically reducing the time from “pipeline red” to “team knows what to fix.”
- Bug report writing. AI can take raw failure information: observed behaviour, logs, reproduction steps, and produce a structured, developer-ready bug report, reducing the back-and-forth between QA and development.
- Accessibility audit documentation. AI can review accessibility testing audit data and generate detailed WCAG-aligned reports, saving significant time on the documentation side of compliance work.
- Performance test script generation. AI can generate performance test scripts from plain-language scenario descriptions, making load testing more accessible across teams whose members may not all have k6 or JMeter expertise.
Real-World Example: AI-Assisted Test Case Generation for a Checkout Flow
A QA engineer is asked to write test cases for a major checkout flow update: new address validation, revised payment options, and a new order confirmation email trigger. Normally this would take three to four hours.
With an AI tool, the workflow changes. Twenty minutes of writing a well-structured prompt: covering acceptance criteria, affected screens, user journey, edge cases, and tech stack context, produces eighty draft test cases in minutes. The engineer spends forty-five minutes reviewing. The AI captured most standard scenarios well but missed two domain-specific edge cases: a known gateway behaviour when a card is declined mid-authorisation, and a locale-specific address format requirement for Germany. Both are added manually.
Total time: one hour fifteen minutes instead of four. Coverage is wider because the AI did not skip boundary conditions the way a tired engineer might late in the afternoon. The review step is not optional. It is the point where domain knowledge enters and the output becomes trustworthy.

Real-World Example: Using AI to Triage a CI/CD Failure Spike
A QA team wakes up to 240 test failures in their overnight CI/CD pipeline. Without AI assistance, this means reading through failure logs, stack traces, and recent commit diffs for most of the day.
With AI-assisted failure analysis, the team feeds the failure logs, stack traces, and a code change diff into the analysis tool. Within minutes, the AI clusters the 240 failures into four groups: 178 failures sharing a root cause in a database connection pool configuration change; 31 failures tied to a breaking API schema change; 19 pre-existing flaky tests unrelated to any recent change; and 12 genuine new defects introduced in the current sprint.
The team now knows exactly where to focus. Triage time drops from five to six hours to approximately forty minutes. This is the kind of shift we documented in our post on From Automation-First to AI-First Quality Engineering: JigNect’s Journey Toward Scalable Software Quality.
Side-by-Side Comparison: Testing AI Systems vs Testing with AI
| Dimension | Testing AI Systems | Testing with AI |
|---|---|---|
| What is being tested | The AI model or AI-powered feature itself | Traditional software, using AI as a testing tool |
| Primary challenge | Non-determinism, bias, drift, hallucination | Prompt quality, AI output review, workflow integration |
| Success criteria | Output properties, fairness, accuracy over time, safety | Speed, coverage breadth, defect detection rate |
| Skills required | ML concepts, statistical reasoning, data quality, adversarial thinking | Prompt engineering, test design, critical output review |
| Applies when | Your product uses AI as a core component | Your QA team wants to move faster and cover more ground |
| Risk if done wrong | Biased outputs in production, hallucination, safety failures, regulatory exposure | Over-reliance on AI-generated tests, missed domain edge cases |
| Monitoring requirement | Continuous: models drift over time | Per test cycle |
| Human oversight needed | High: especially for fairness and safety dimensions | Moderate: review of AI output is always required |
Why Traditional QA Methods Are Not Enough for AI Systems
Most QA frameworks in wide use today were designed for deterministic software. Requirements come in, developers write code, QA writes tests against defined expected outputs. This pipeline works well for traditional features. AI systems break it at multiple points.
The Determinism Problem
Every automated regression test rests on a simple assumption: given the same inputs, the system produces the same outputs. This assumption is what makes it possible to record expected results once and compare against them indefinitely.
When you introduce an AI component, this assumption no longer holds. Traditional test assertions based on exact value matching will either produce floods of false positives or miss genuine quality degradation because the output changed in a direction the test did not anticipate. This is not fixable within traditional test frameworks. It requires a different evaluation layer designed specifically for the probabilistic nature of AI outputs.
Redefining What Pass and Fail Mean for AI
Effective AI system testing requires moving from output-matching to property-checking. The properties that define a valid AI output will differ by system type. Some can be automated. Others require periodic sampling and manual assessment. All need to be defined explicitly before testing begins, because no amount of testing can discover what “good” looks like if the team has not agreed on it in advance.
Real-World Example: A Recommendation Engine That Passed All Tests and Still Failed in Production
An online retail platform adds an AI-powered product recommendation engine. The QA team writes tests verifying the engine returns products when queried, that response times are within budget, and that recommended items are from the active catalogue. Every test passes. The feature ships.
Within six weeks, analytics surfaces a pattern: recommendation relevance is significantly lower for users in one region. The engine’s training data underrepresented that region. The tests passed because they never checked for fairness or representational accuracy across user segments. They verified the engine worked, not that it worked equitably.
The fix required retraining the model with a more representative dataset and adding a fairness evaluation step to the QA process, a significantly more expensive intervention post-launch than pre-launch. This is precisely why AI/ML testing is a distinct specialisation, not an extension of traditional automation testing.
Building a QA Strategy That Covers Both
If your team is building AI-powered products while also wanting to use AI to accelerate the QA process, you need a strategy that addresses both disciplines without conflating them. The starting point is an honest audit: which challenge is more acute right now?
Skills Needed for AI System Testing
- Foundational ML concepts. QA engineers do not need to be data scientists, but they need to understand training data, model drift, precision vs recall, confidence scores, and the difference between model behaviour and model quality.
- Data quality assessment. A significant portion of AI quality problems originate in training data. Being able to evaluate whether test datasets are representative, and whether the data pipeline feeding the model in production is functioning correctly, is a core skill.
- Adversarial thinking. Actively trying to manipulate, confuse, or break the AI system through unusual, boundary-pushing, or deliberately misleading inputs is part of thorough AI system testing, not an optional extra.
- Property-based evaluation design. Someone on the team needs to be able to define what “good output” means for a specific AI system, then design and implement the evaluation logic that checks for it.
- Production monitoring. Testing AI systems does not end at launch. Monitoring for drift, degradation, and unexpected shifts in model behaviour as real-world usage evolves is an ongoing responsibility.
Skills Needed for Testing with AI
- Prompt engineering. Writing effective prompts for test case generation, failure analysis, and bug report production is a learnable skill that improves with deliberate practice. Teams that invest in building a shared library of well-crafted, reusable prompts and a structured way to manage them across projects, see consistently better AI outputs than teams that approach each request ad hoc. Prompt management platforms like Orkestraa by AIdriventesting.ai are specifically designed to solve this: storing, versioning, and sharing QA-specific prompts across teams so that what works in one sprint is not lost before the next.
- Critical review of AI output. AI-generated test cases, test data, and reports must always be reviewed by an experienced QA engineer before use. The review is not a rubber stamp. It is the checkpoint where domain knowledge enters and the output becomes trustworthy.
- Workflow integration. Slotting AI tools into existing QA workflows, CI/CD pipelines, and reporting structures without creating new bottlenecks requires planning. The most effective AI-assisted processes are ones where AI handles repetitive, well-defined tasks and people focus on judgment-intensive work.
We also explored how structured thinking about test scope connects directly to getting better outputs from AI in our post on How to Improve Automation Test Coverage Without Increasing Execution Time.
Tooling Considerations for Each Approach
Common Mistakes Teams Make in Each Category
- Applying traditional regression testing to AI components. When a product adds an AI-powered feature, many teams assume their existing test suite extends to cover it. It does not. AI components require additional evaluation layers for non-determinism, hallucination, drift, and fairness that conventional automation cannot provide.
- Skipping the property definition step. You cannot test for quality you have not defined. Before an AI feature launches, the team needs to agree on what acceptable behaviour looks like. Testing cannot answer these questions. It can only verify against answers that already exist.
- Treating AI-generated test artefacts as automatically trustworthy. AI tools can produce test cases that look comprehensive but miss critical domain-specific scenarios. Human review is not a nice-to-have. It is the checkpoint that keeps AI-assisted testing grounded in domain reality.
- Underinvesting in prompt quality. The output quality from AI testing tools is directly proportional to the quality of the prompts driving them. Teams that use generic, vague prompts get generic, vague outputs. The discipline of prompt writing, and building a shared library of high-quality prompts, is one of the highest-ROI investments a QA team can make.
- Stopping AI system testing at launch. AI models degrade over time. Treating launch as the end of AI system validation is one of the most common and most costly mistakes. Production monitoring, periodic holdout evaluation, and drift detection need to be part of the ongoing quality programme.
- Confusing AI safety testing with AI quality testing. Safety testing (ensuring the model does not produce harmful outputs) and quality testing (ensuring the model produces accurate and useful outputs, are distinct activities. Both are necessary. Teams in regulated industries carry particular risk if they address only one without the other.
The Competitive Advantage of Getting Both Right
The teams that build genuine, durable advantage in software quality over the next several years are the ones that develop capability in both directions simultaneously. They validate their AI-powered products with the rigour those products demand: property-based evaluation, adversarial testing, fairness checks, and continuous production monitoring. And they equip their QA teams with AI tools that allow them to work faster and cover more ground, with the review processes that keep those outputs reliable.
There is also a resourcing dimension worth noting. Teams that use AI tools effectively in their QA workflow are able to achieve higher test coverage without proportionally increasing execution time, a dynamic explored we explored in detail in our post on improving automation test coverage without increasing execution time. That freed-up capacity can be redirected toward the higher-complexity work of AI system validation, creating a reinforcing cycle.
The shift from a test-at-the-end mindset to quality embedded across the delivery lifecycle, which we documented in The Role of QA in DevOps: From Shift-Left Testing to Continuous Delivery, is part of this same broader transformation.
How JigNect Approaches Both Disciplines
At JigNect Technologies, both of these challenges come up regularly across our engagements with software teams around the world.
For teams building AI-powered products, our AI/ML testing practice focuses on the validation methods that traditional testing cannot provide: model accuracy evaluation, bias and fairness testing, adversarial input testing, and production monitoring strategy. We have worked through these challenges across fintech, healthcare, and SaaS contexts, each of which brings regulatory and quality expectations that standard QA methods do not fully address.
For teams looking to modernise their QA workflow with AI tools, our automation testing practice has integrated AI-assisted approaches for test case generation, failure analysis, and coverage optimisation, with explicit human-in-the-loop review at each stage.
If you are figuring out which of these challenges is most pressing for your team right now, get in touch and we can talk through your specific situation.
Not sure where to start?
Whether you are shipping a product with AI features or looking to bring AI into your QA workflow, JigNect can help you figure out the right approach for your team and your context
Closing Thoughts
Testing AI systems and testing with AI are not two names for the same discipline. They require different thinking, different skills, different tools, and different success criteria.
If your team is shipping a product that uses AI as a core component, the question is whether your validation approach is designed for what makes AI systems actually fail: non-determinism, data quality gaps, fairness issues, adversarial vulnerability, and temporal drift. Traditional functional testing and automation testing are necessary but not sufficient on their own.
If your QA team is adopting AI tools to work more efficiently, the question is whether you have built the review processes and prompt quality standards that make those tools reliable contributors to your pipeline, rather than sources of plausible-looking but incomplete test artefacts.
Both investments are worth making. Both are becoming expected capabilities for teams that take software quality seriously. And the teams that build genuine expertise in each, rather than treating them as the same problem, are the ones building quality programmes that scale.
Witness how our meticulous approach and cutting-edge solutions elevated quality and performance to new heights. Begin your journey into the world of software testing excellence. To know more refer to Tools & Technologies & QA Services.
If you would like to learn more about the awesome services we provide, be sure to reach out.
Happy Testing 🙂


")