
In the ever-evolving field of software testing, ensuring the integrity and functionality of applications is a fundamental goal. QA automation engineers act as the forefront defenders, carefully designing and running test scripts to assess performance and uncover any potential issues. In this context, a thorough understanding of data structures becomes essential. This blog examines the crucial role that data structures play in QA automation, emphasizing their importance and discussing fundamental structures that enable QA engineers to create robust and effective test automation scripts.
- 🔍The Significance of Data Structures in QA Automation
- 🎯 Data Structures for QA Automation 🎯
- Arrays
- Key Points about Arrays
- Using Arrays in Real-World Scenarios
- Generics
- Lists
- Declaring and Initializing Lists
- Adding Items to a List
- Accessing Elements of a List
- Removing Items from a List
- Sorting a List
- Searching in a List
- List Capacity and Count
- Converting Lists to Arrays
- Linked Lists
- Hash Set
- Dictionary
- Key points to note about the Dictionary class:
- Example of Dictionary ⤵️
- Queue
- Stack
- Stack Methods
- Tuple
- Tuple is handy for:
- Conclusion
🔍The Significance of Data Structures in QA Automation
Data structures are fundamental building blocks in software development and testing. They are essential for organizing, storing, and manipulating data efficiently. Here’s why data structures matter for QA automation engineers:
🟢 Efficient Data Management: Automation engineers deal with various types of data, such as test cases, test data, and test results. Properly chosen data structures can significantly improve the efficiency of data management and retrieval.
🟢 Improved Test Script Performance: Well-designed data structures can optimize the performance of your test scripts. This is crucial when you need to execute a large number of test cases quickly.
🟢 Simplified Test Data Handling: QA automation often involves working with test data, which can vary in complexity. Using the right data structures simplifies data handling and ensures that tests are conducted accurately. Additionally, dictionary data structures can be particularly useful in organizing and managing test data.
🟢 Scalability: As software projects grow, the volume of test data and test cases also increases. Scalable data structures allow automation engineers to handle larger datasets without sacrificing performance.
🎯 Data Structures for QA Automation 🎯
Now that we understand why data structures are essential for QA automation, let’s explore some data structures that are particularly valuable in this context.
Arrays
An array is a collection of elements of the same data type, whether they are value types (like integers or floats) or reference types (like objects).
Arrays provide a way to store and access multiple values of the same type sequentially.
Key Points about Arrays
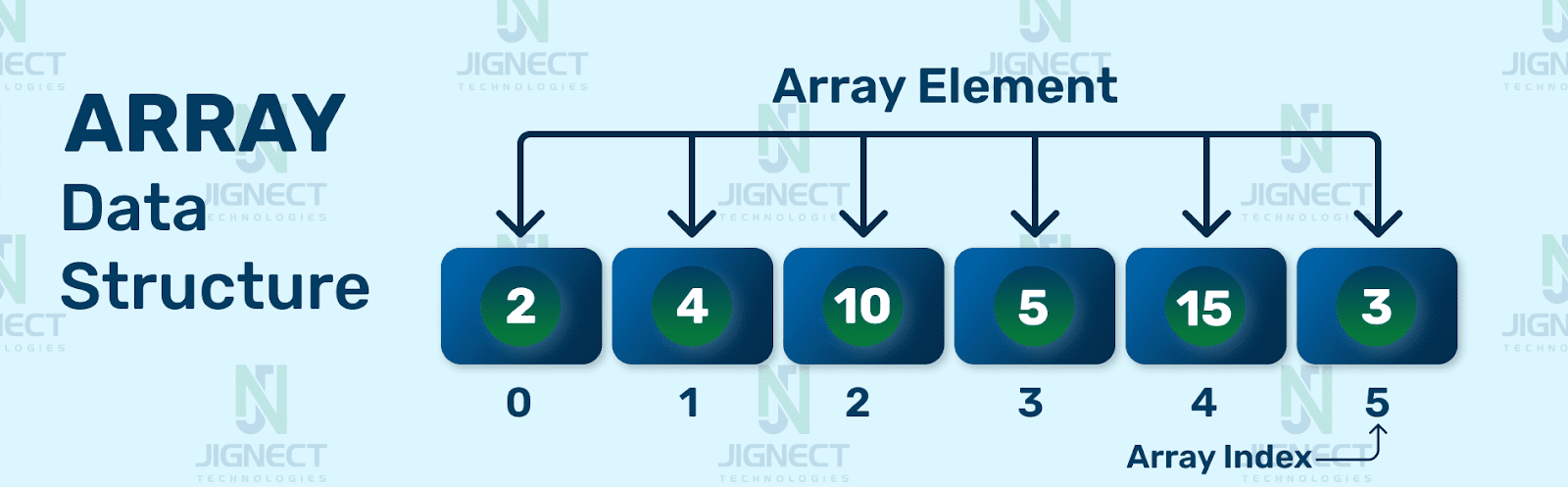
1. Indexing: Arrays in C# are zero-based, which means the first element is at index 0, the second element is at index 1, and so on.
2. Fixed Size: When you create an array, you specify its size, and that size cannot be changed dynamically. If you need to store more elements than the array’s size, you must create a new, larger array and copy the elements from the old array to the new one.
3. Homogeneous: Arrays are homogeneous, meaning they can only store elements of the same data type. While some programming languages, like JavaScript, allow mixed data types in arrays, C# enforces strict typing.
In the modern world most of the QA’s already use more flexible and easier to manage generic wrappers of the Array e.g. List in C# and ArrayList in Java.
Anyway Array still can be useful in the modern days too.
Using Arrays in Real-World Scenarios
1. Building a Comma-Separated URL Query Parameter:
Suppose you want to build a URL with a list of comma-separated IDs as a query parameter. You can use an array to achieve this:
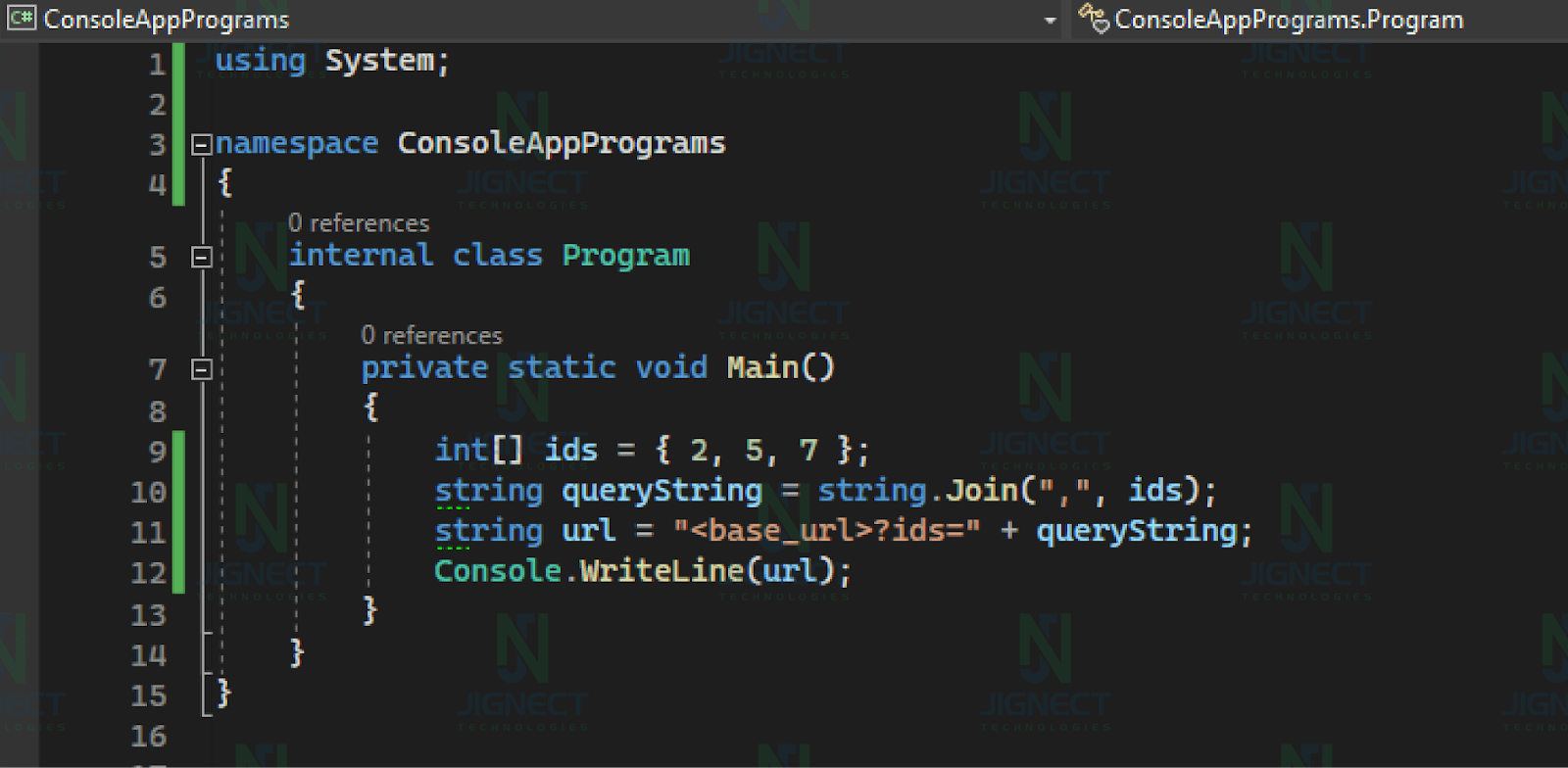
In this code, we create an array `ids` containing the IDs and then use `string.Join` to concatenate them with commas for the query parameter.
2. Extracting and Summing Numbers from a String:
If you have a string containing numbers and characters and you want to extract and sum the numbers, you can do so with an array:
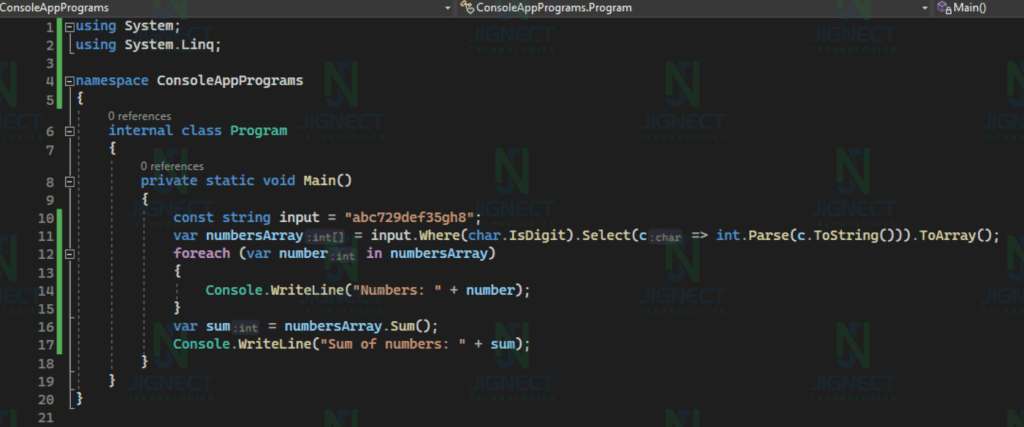
In this example, we create an array `numbersArray` by extracting the digits from the input string and then sum them to get the result.
Generics
Generics are a powerful feature that allow you to create classes, methods, and data structures with placeholders for data types. These placeholders are replaced with specific types at compile time. Generics provide flexibility and type safety because they enable you to write code that can work with different data types while preserving compile-time type checking.
- C# and Java has built-in generics like List and Dictionary.
- Generics can have constraints, like requiring a reference type or non-null type.
- Generics provide helpful methods for data management.
- You can create your custom generics.
- Declare a generic type by adding a type parameter in angle brackets, e.g., TypeName<T> where T is a type parameter.

Example of Custom Generics ⤵️
Suppose you are developing a testing project for a REST API microservice, and you know that the microservice always returns two pieces of information: a status code (always of the same data type, typically an enumeration like `HttpStatusCode`) and some data (the type of which can vary depending on the API endpoint).
You can create a generic model, `RestResponse<T>`, that can be reused for all your API endpoints:
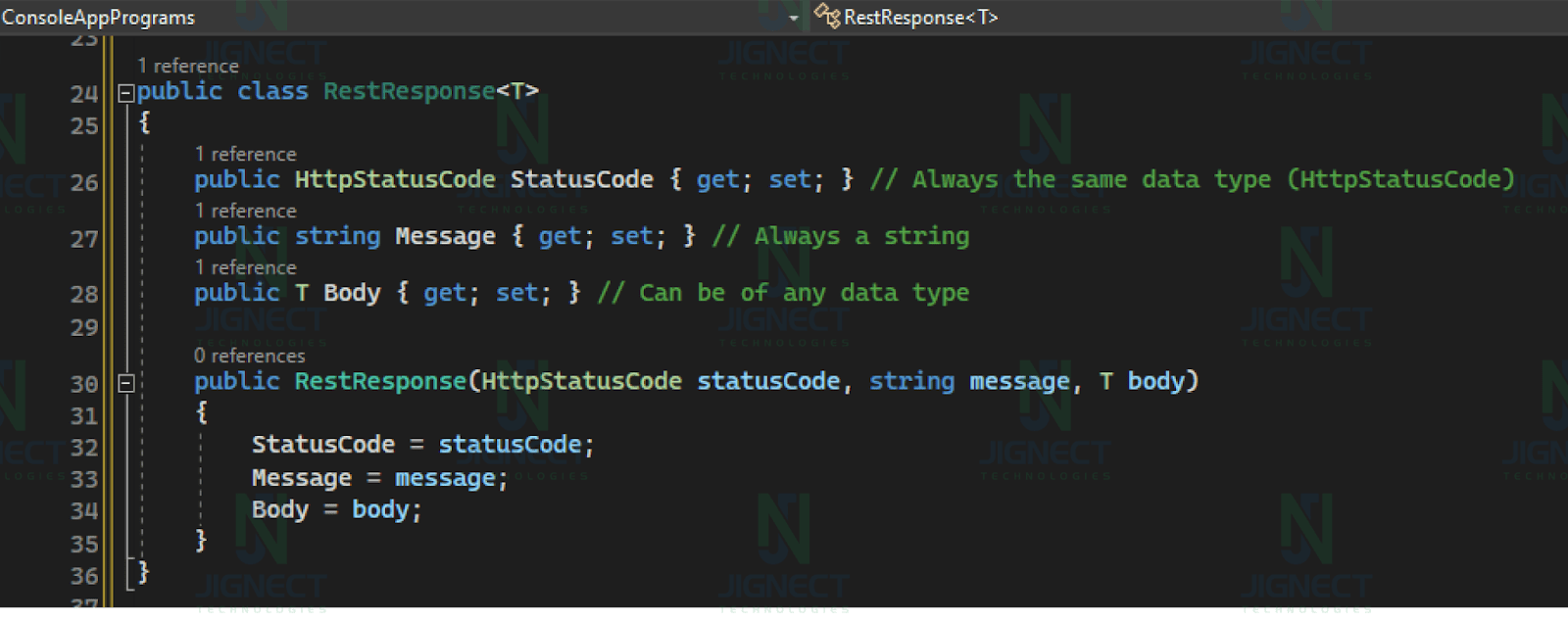
In the above example, we’ve created a `RestResponse<T>` model that includes properties for the status code, a message (which is always a string), and the response body (of any data type `T`). This allows you to handle responses from your REST API in a generic way, accommodating different response data types while ensuring type safety
When you create methods to parse JSON data or handle API responses, you can use this `RestResponse<T>` model, and the type `T` will be determined based on the specific response data type you expect.
Lists
Lists are a commonly used data structure similar to ArrayList in Java. They are essentially generic classes used to store and manage collection objects. Lists are dynamic in size, enabling the addition or removal of elements at runtime, and can store items of any data type, including custom types.
It also contains many methods that help you to manage data easily.
Now, let’s explore these features in more detail ⤵️
Declaring and Initializing Lists
- Using the List Constructor: You can create a new List by using the List constructor and specifying the data type of the elements it will store.

- Using Collection Initializers: You can also initialize a List using a collection initializer, which lets you specify the initial elements within the declaration.

Adding Items to a List
- Add() Method: Add a single item to the end of the List.
- AddRange() Method: Add a collection of items to the end of the List.
Accessing Elements of a List
- Using Indexers: Access individual elements of a List using indexers.
- ForEach loop: Iterate through all the elements of a List using a ForEach loop.
Removing Items from a List
- Remove() Method: It removes the first occurrence of a specified item.
- RemoveAt() Method: It removes the item at a specified index.
- RemoveRange() Method: It removes a range of elements starting from a specified index.
Sorting a List
- Sort() Method: Sorts the elements of the List using the default comparer for the data type.
- Comparison Delegate: You can also sort a List using a custom comparison delegate. This allows you to define your own sorting criteria.
Searching in a List
- Find() Method: It searches for an element that matches a specified predicate.
- FindAll() Method: It returns a new List containing all elements that match a specified predicate.
List Capacity and Count
- The Count property returns the number of elements in the List, while the Capacity property returns the current capacity of the List. The capacity is automatically increased as elements are added to the List.
Converting Lists to Arrays
- You can convert a List to an array using the ToArray() method.
Example of Lists ⤵️
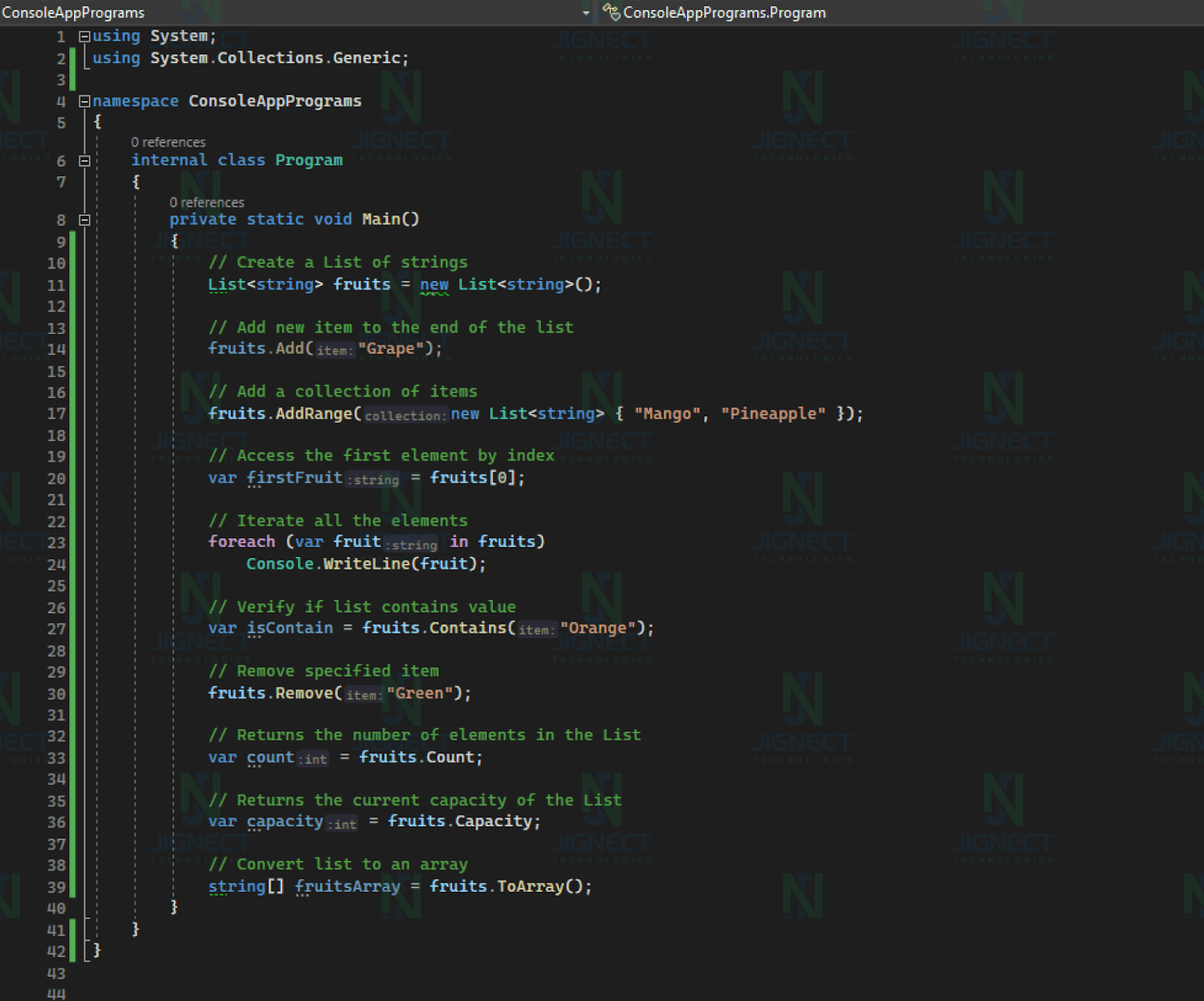
Above example demonstrates various operations on a List of strings. It starts with an initial list of fruits, adds new fruits, accesses elements, iterates through the list, checks for the presence of a value, attempts to remove a value, and retrieves the count and capacity of the list.
There are many more methods available. It’s a good idea to get to know all of these methods.
The List is an essential data structure, and to become skilled at working with list data, practice is key. Additionally, there are libraries like LINQ (for C#) and Stream API (for Java) that can greatly enhance your ability to manage lists effectively.
There are countless examples of how Automation QA professionals use lists. One of these examples involves finding and storing WebElements from a webpage, making it easier to manage them for future tasks.

Using a similar approach, we apply it to our data models. For example, when dealing with API responses, we anticipate receiving a certain number of records, but we don’t have the exact count. So, we define it as a List<DataType>.
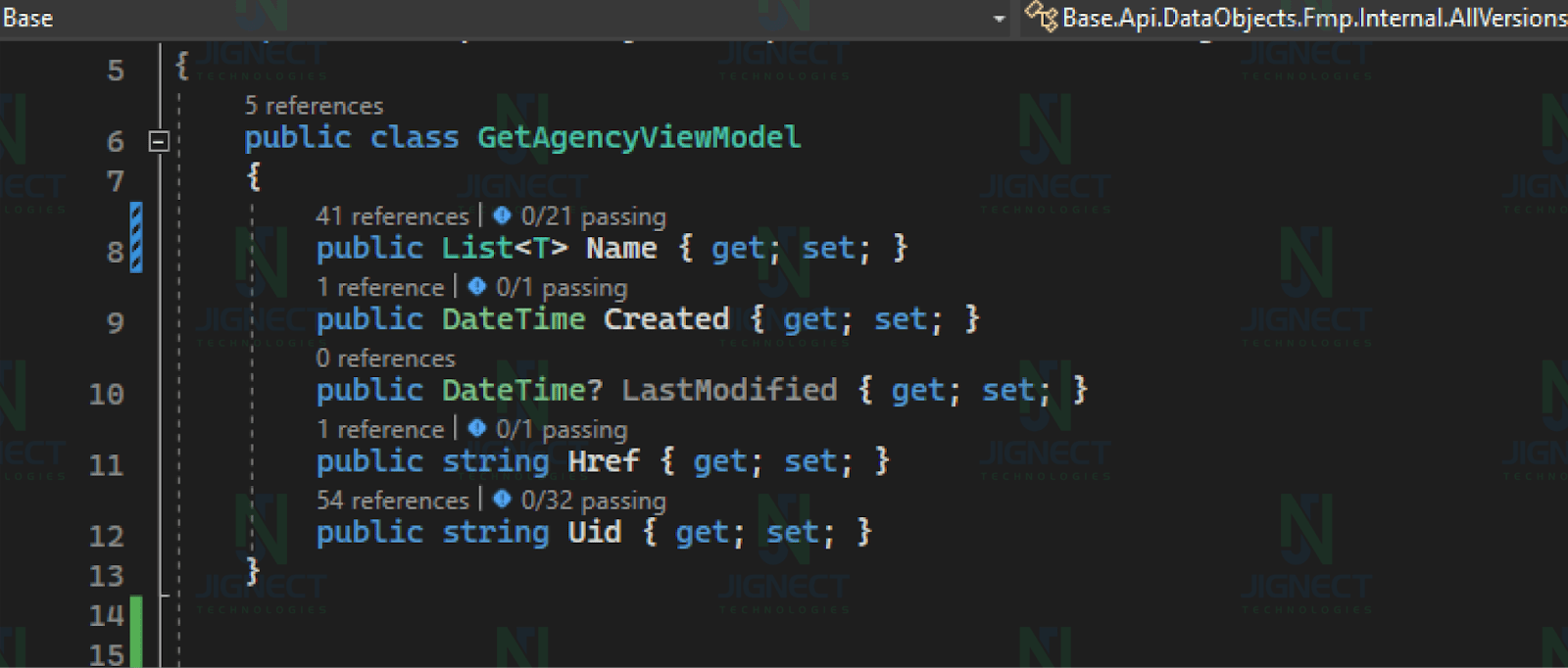
Note: In Java, the equivalent of C# List is called ArrayList.
Linked Lists
A linked list is a linear data structure, in which the elements are stored in the form of a node. Each node contains two sub-elements. A data part that stores the value of the element and next part that stores the link to the next node as shown in the below image:
With Linked Lists, we don’t have direct access to indexes. We can only access the current element and the element(s) linked to it, which are typically referred to as “nodes”.
In the following example, each element contains information about itself and can access the next element. However, we can’t directly jump from the first element to the last one. To access the last element, we must traverse through each element in sequence.
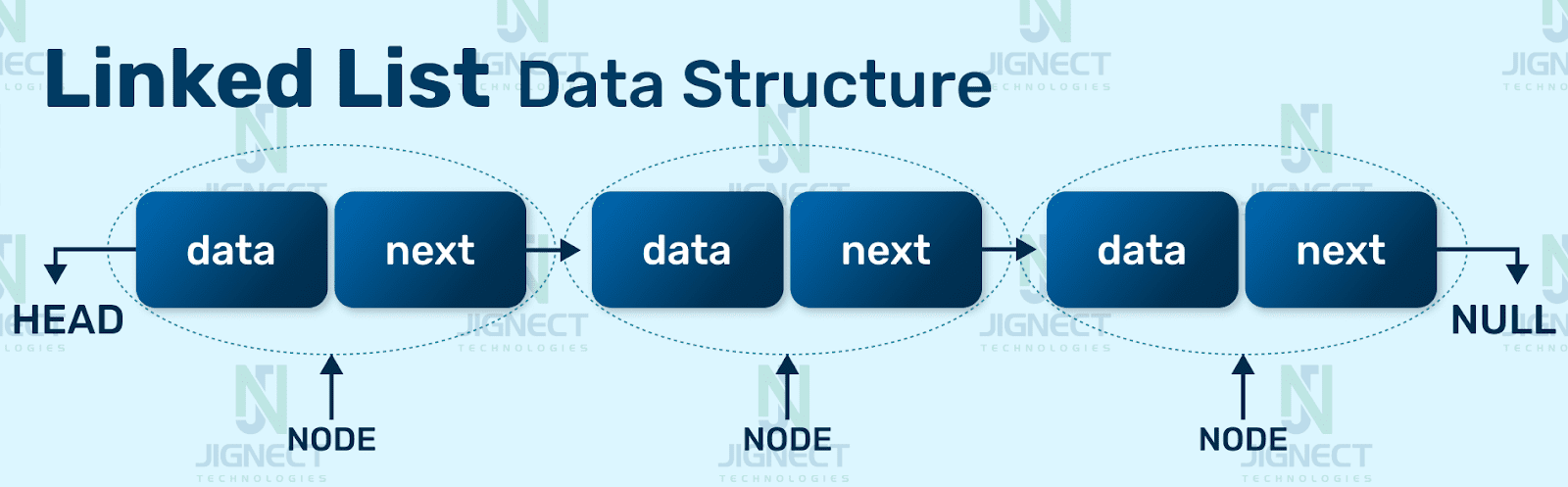
The same principle applies to Two-Directional Linked Lists, but in this case, each element also has knowledge of the previous element.
It has lots of ways to make handling data easier for you.
Example of Linked List ⤵️
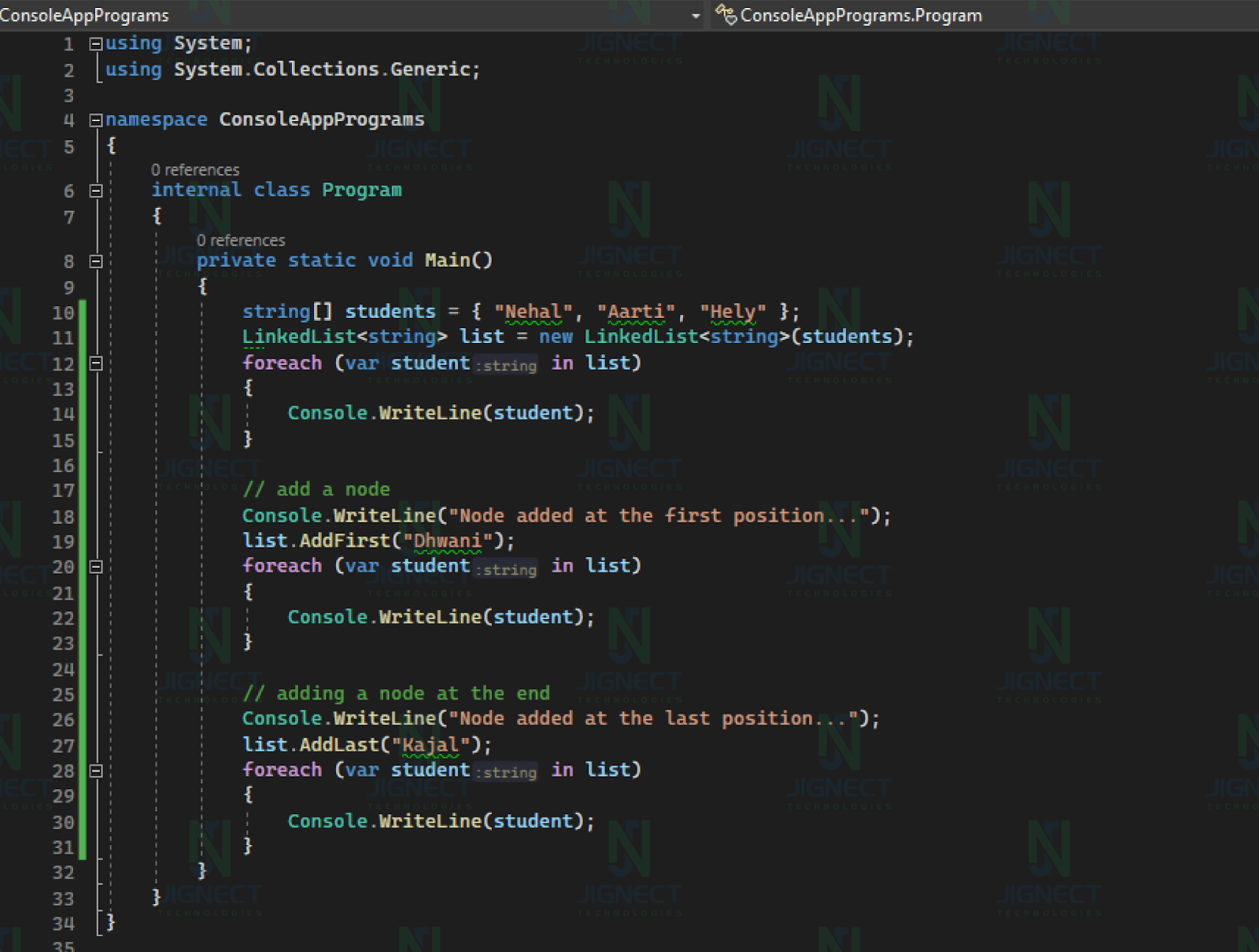
Above example demonstrates the creation and manipulation of a linked list of student names. It starts with an initial list of students, adds a new student at the beginning, and then adds another student at the end. The program also displays the contents of the linked list at each step to illustrate the changes.
Hash Set
A HashSet is one of the implementations of a Hash Table. It’s a collection that contains no duplicate elements and doesn’t maintain any specific order for its elements. Hash set is defined under System.Collections.Generic namespace.
To understand its usefulness, let’s consider a scenario where we have results from various sources, and we want to combine them while ensuring that duplicate values are removed.
In this case, we can create a HashSet<T> and add all the results to our set. The HashSet will automatically take care of eliminating duplicate values. This makes it a convenient choice for scenarios where you need to work with unique elements.
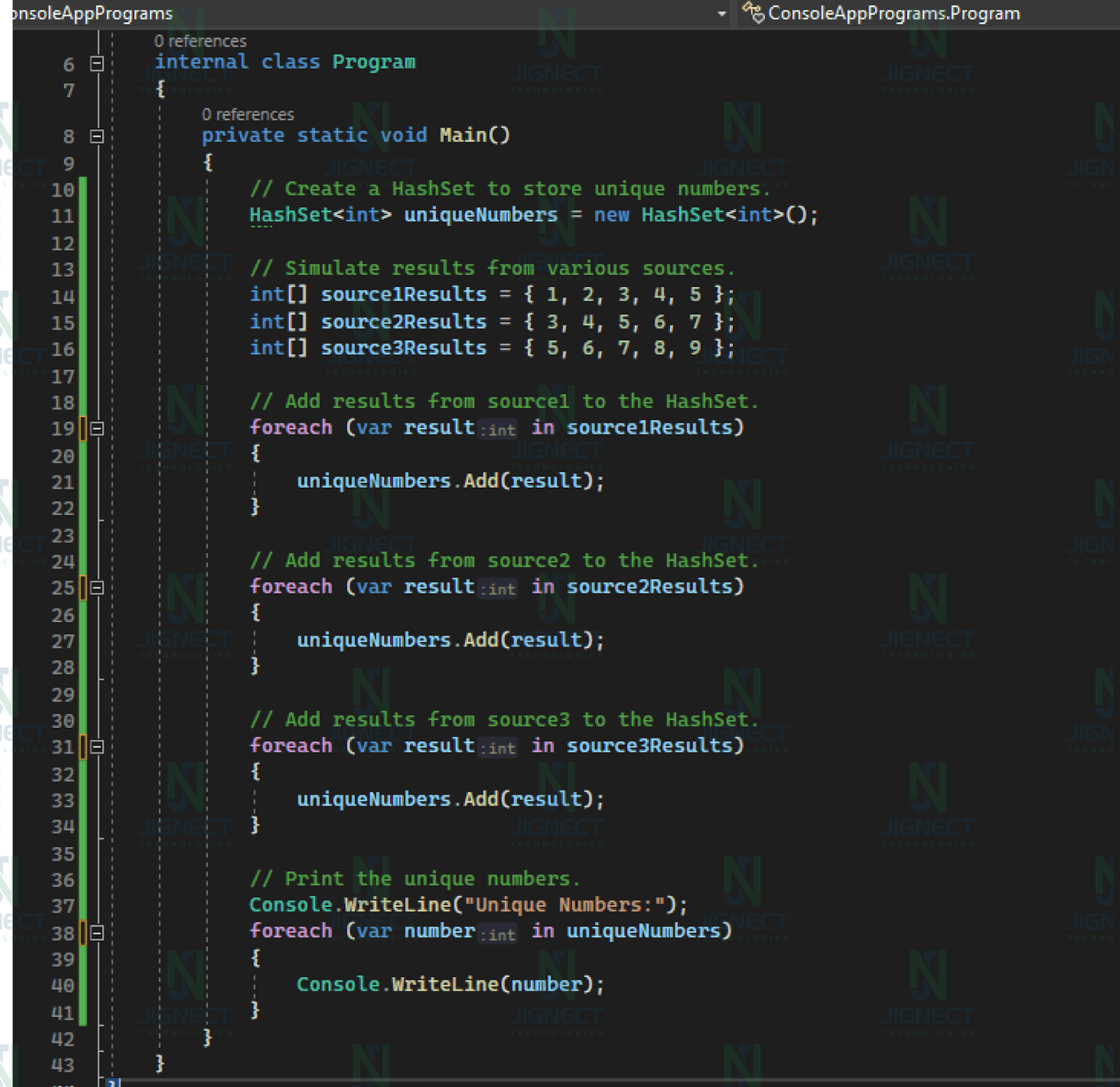
This example demonstrates how a HashSet can efficiently handle and remove duplicate values when combining data from multiple sources.
It’s worth noting that there’s also an implementation of a SortedSet, which not only ensures uniqueness but also automatically sorts the values inside it based on their natural order or a custom comparison logic.
While you might not use HashSet or SortedSet frequently, they can be incredibly useful in situations where you need to efficiently manage and process collections of unique elements, like removing duplicates from combined data.
Dictionary
Dictionary class uses the concept of hashtable.Dictionary is a generic collection that consists of elements as key/value pairs that are not sorted in an order. The keys must be unique, but the values can be duplicated. Dictionaries are implemented as hash tables so their keys can quickly access them. This makes them particularly useful in data structure testing, where quick access to elements is crucial.
Dictionary is defined under System.Collections.Generic namespace.
Key points to note about the Dictionary class:
- The Dictionary class implements the,
- IDictionary<TKey,TValue> Interface
- IReadOnlyCollection<KeyValuePair<TKey,TValue>> Interface
- IReadOnlyDictionary<TKey,TValue> Interface
- IDictionary Interface
- In the Dictionary, the key cannot be null, but value can be.
- In the Dictionary, the key must be unique. Duplicate keys are not allowed if you try to use a duplicate key then the compiler will throw an exception.
- In the Dictionary, you can only store the same types of elements.
- The capacity of a Dictionary is the number of elements that a Dictionary can hold.
Dictionary is the second most popular data structure after List.
Example of Dictionary ⤵️
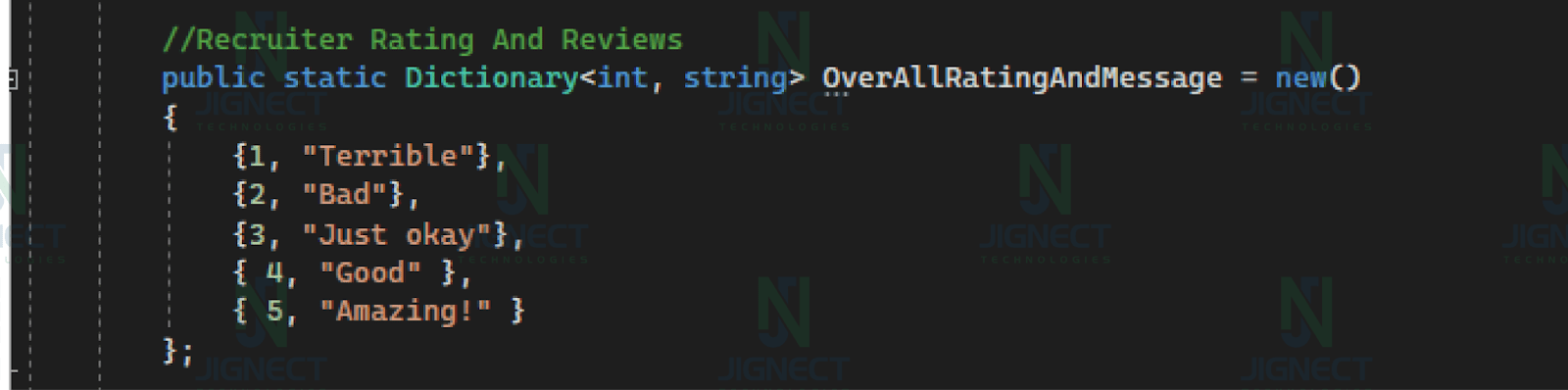
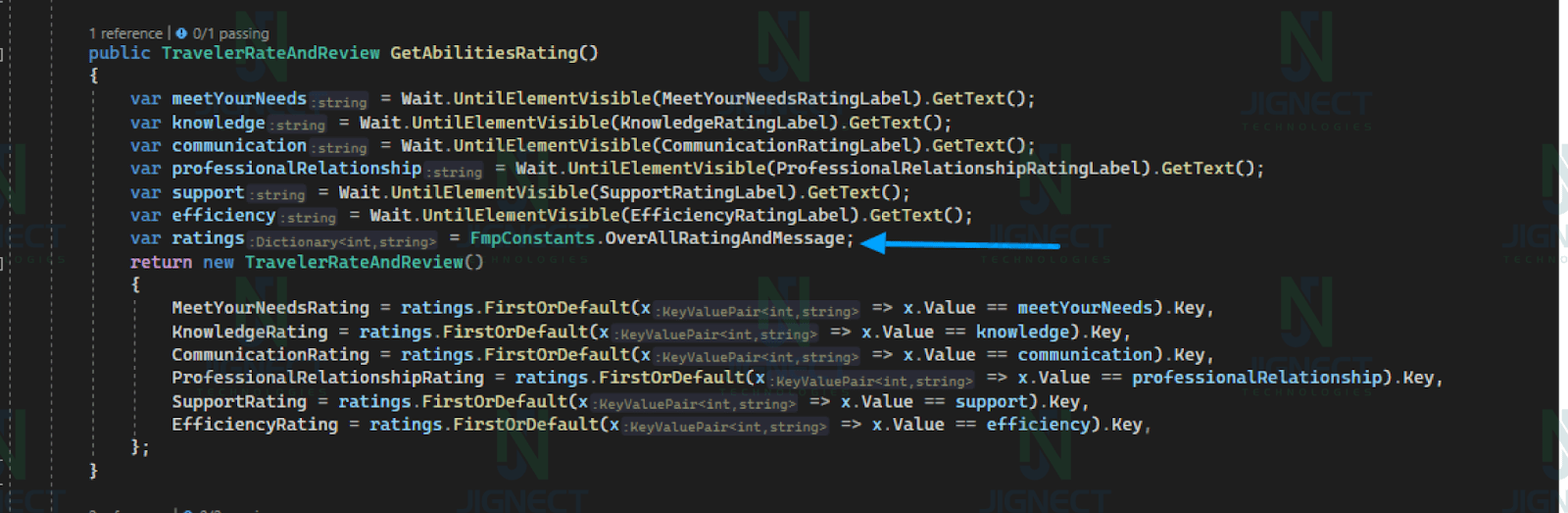
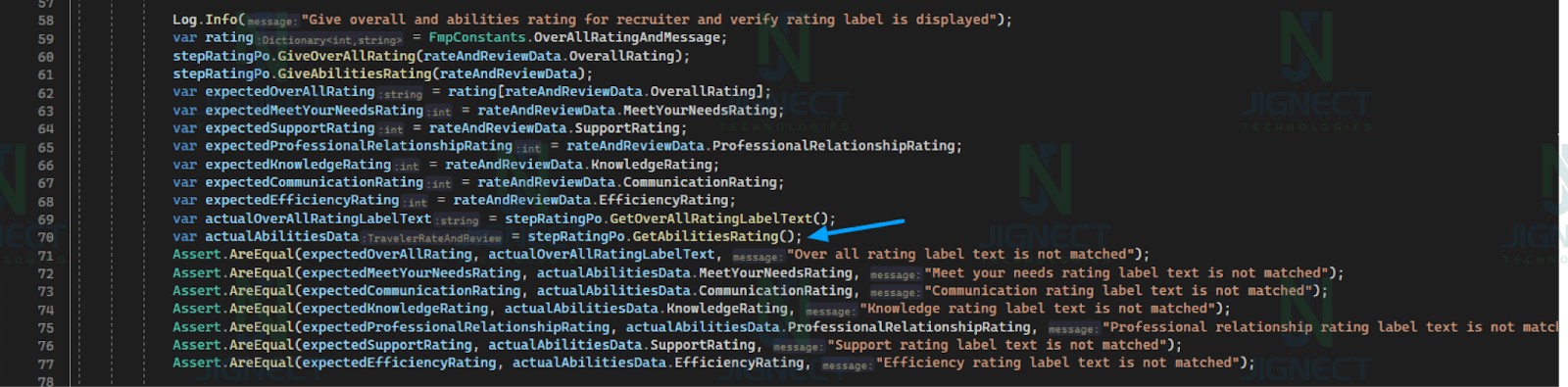
In this example, a dictionary maps integer ratings to corresponding string messages. Ratings for various abilities are retrieved from a web application, and the dictionary is used to map these strings back to integers. The code then logs and verifies the ratings and reviews data, ensuring that they match the expected values.
NOTE: The Java equivalent of Dictionary is called – HashMap.
Queue
A queue is a linear data structure that follows the First-In-First-Out (FIFO) principle. This means that the first element added to the queue is the first one to be removed.
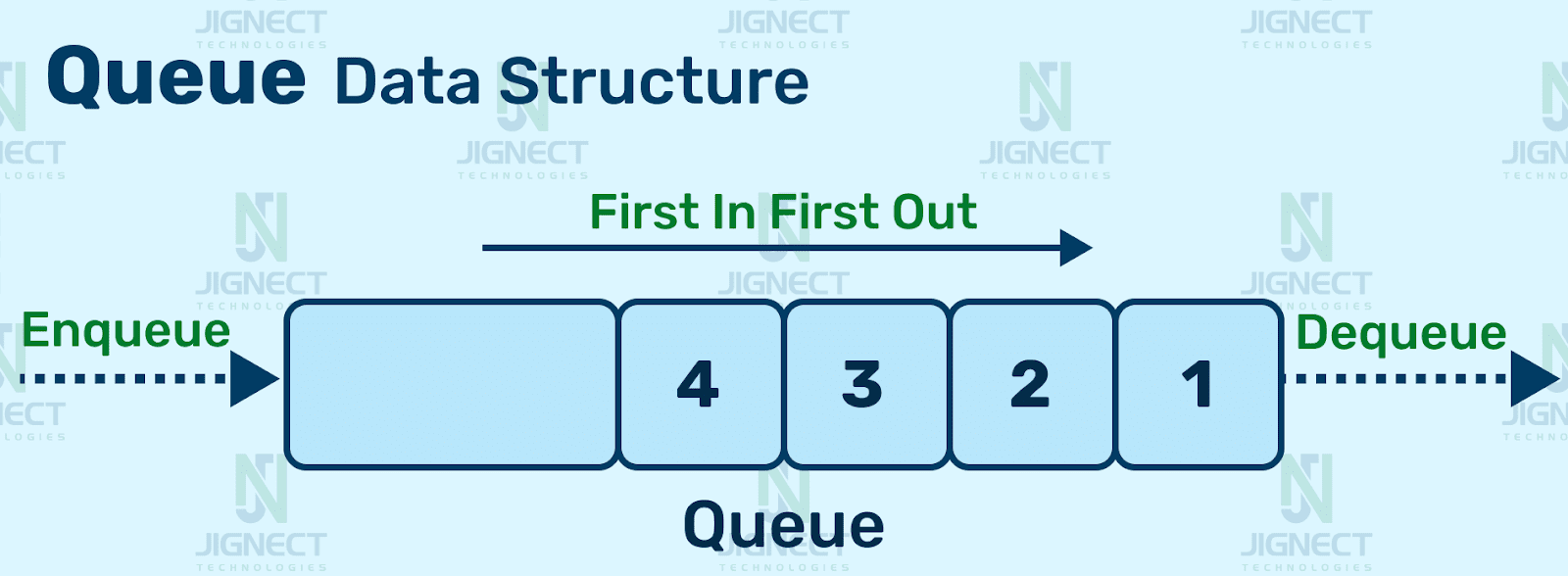
Think of it like waiting in line at a grocery store; the person who arrived first will be the first to check out.
Queues are conveniently implemented using the Queue<T> class in the System.Collections.Generic namespace. This class provides methods for enqueueing (adding) items to the end of the queue and dequeuing (removing) items from the front.
Queue Methods
C# provides 3 major Queue<T> methods. These methods are:
- Enqueue() – adds an element to the end of the queue
- Dequeue() – removes and returns an element from the beginning of the queue
- Peek() – returns an element from the beginning of the queue without removing
Example of Queue ⤵️
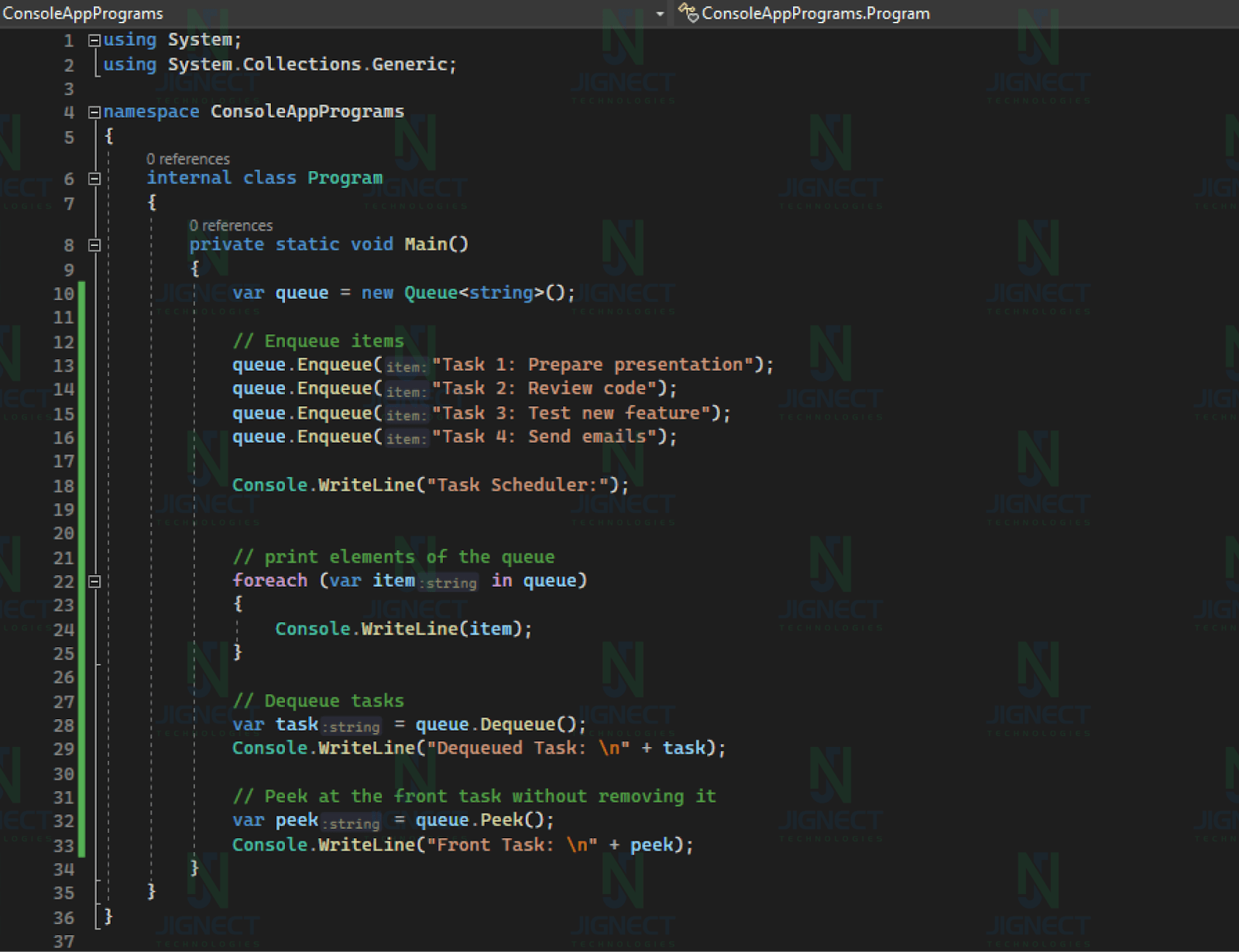
In this example, we use a queue to simulate a simple task scheduling system. Tasks are enqueued in the order they should be executed, and then they are dequeued and executed one by one.
In QA Automation, queues are handy for parallel tasks. For example, if you need to access data from a shared storage system concurrently, queues help manage requests, preventing conflicts and ensuring efficient processing. This simplifies task coordination and enhances automation efficiency.
Stack
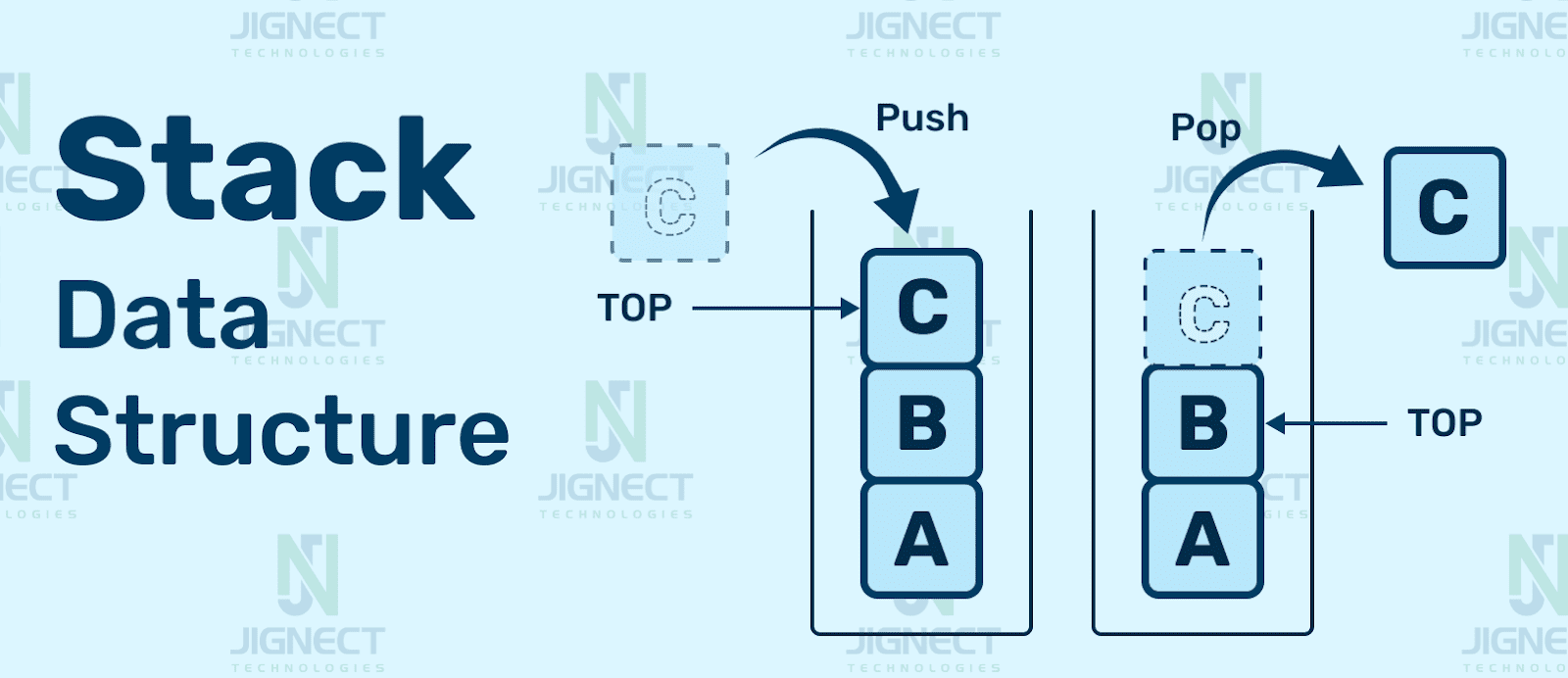
Stack is a generic class that arranges the elements of a specified data type using Last In First Out(LIFO) principles. Think of a stack as a collection of items, where anything you insert in a stack will be placed at the top and if you need to remove something, it will be removed from the top. It can have duplicate elements. It is found in System.Collections.Generic namespace.
When we put an item on the top, we can retrieve it easily from that same position.
Stack Methods
C# provides 3 major Stack<T> methods. These methods are:
- Push() – This method adds element to the top of the stack
- Pop() – This method removes and returns an element from the top of the stack
- Peek() – This method returns an element from the top of the stack without removing
Example of Stack
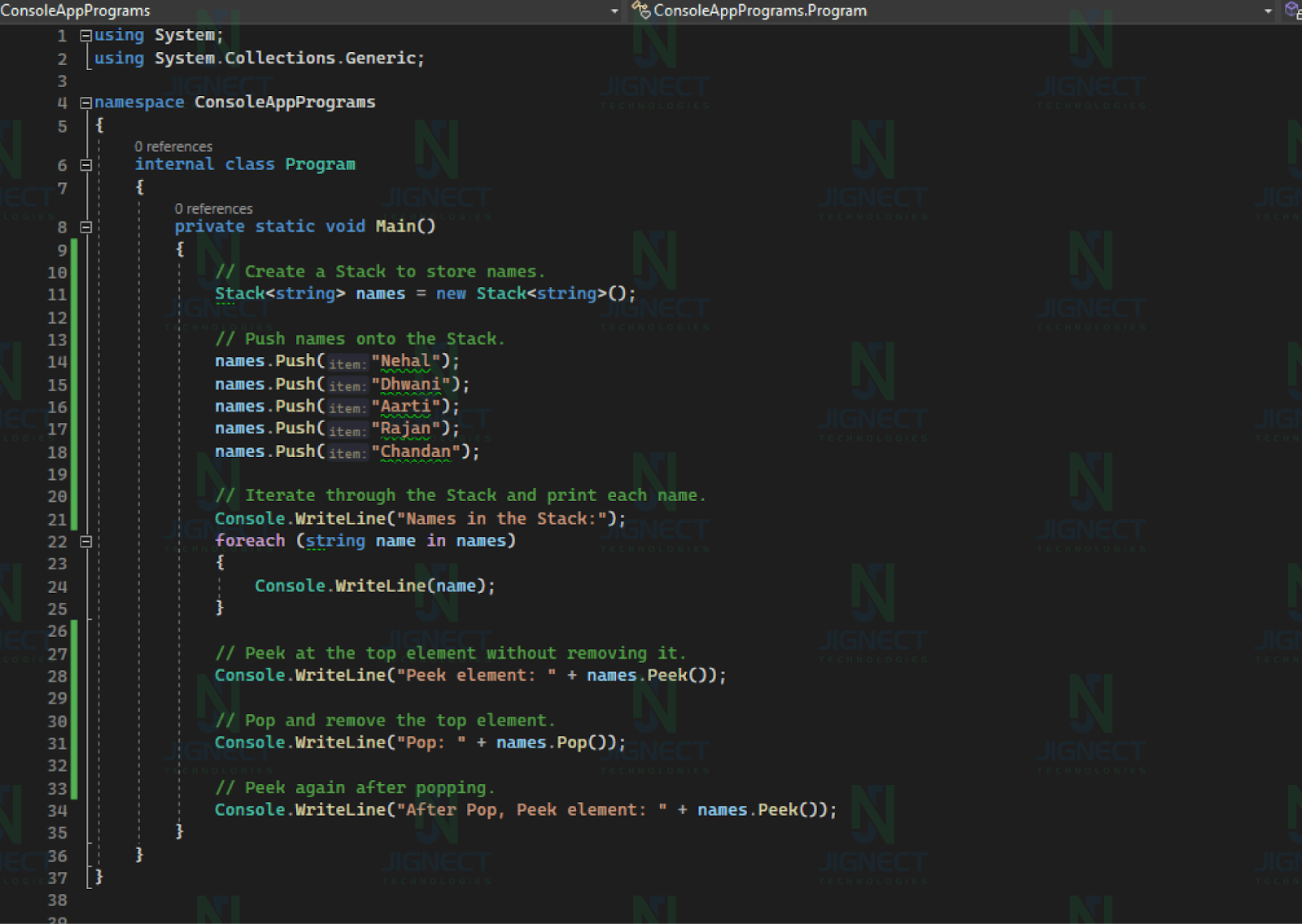
This example uses a ‘Stack’ to manage names. It pushes names onto the Stack, prints them, and demonstrates the Peek and Pop operations. The Stack follows the Last In, First Out (LIFO) principle, meaning the last name added is the first one removed.
Tuple
Tuple is a data structure which gives you the easiest way to represent a data set which has multiple values that may/may not be related to each other. This makes it particularly useful in test data structure scenarios.
Tuple is handy for:
- Holding a single set of data.
- Offering convenient data access and manipulation.
- Returning multiple values from a method without “out” parameters.
- Passing several values to a method using a single parameter.
Example of Tuple ⤵️
We’re using Tuple to store various pieces of information related to user sign-ups. Let me break it down simply:

“SignUpUser1” and “SignUpUser2” are two Tuple variables that hold details about user sign-ups. Each Tuple consists of five parts. `SignUpData`, which represents user sign-up information. Two boolean values (`bool`) for “Created” and “In creation” statuses. Two integer values (`int`) for “current use count” and “max use count.”
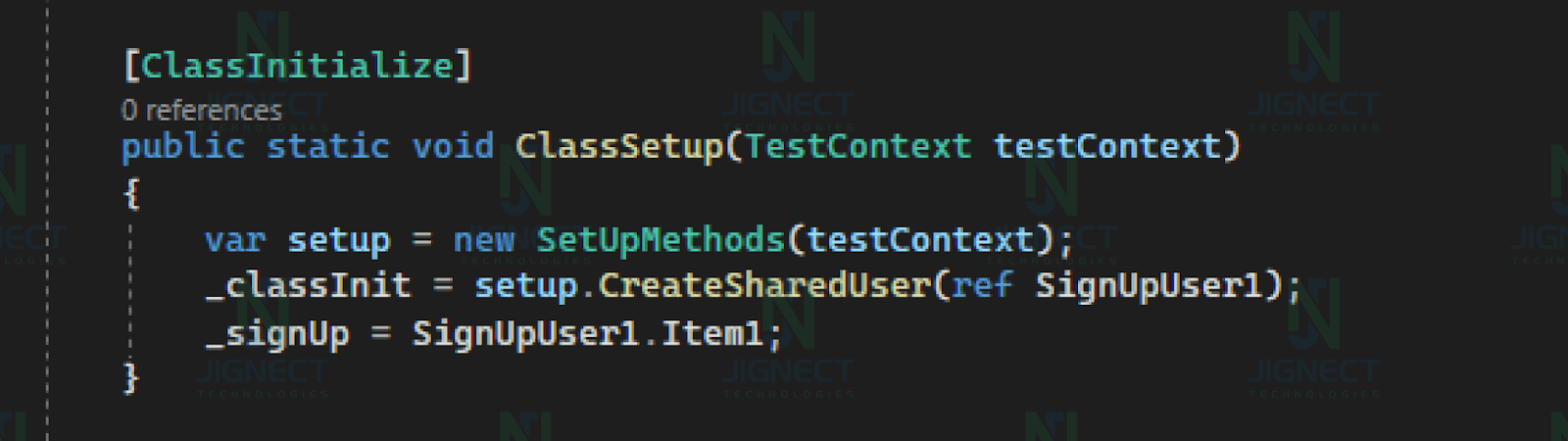
In the `ClassInitialize` method, An instance of `SetUpMethods` is created to set up the testing environment. `SignUpUser1` is used to create a shared user (`_classInit`) by passing a reference to it. `_signUp` is set to the `SignUpData` from `SignUpUser1`.
Conclusion
Data structures are pivotal in the realm of QA automation. They facilitate efficient data management, enhance test script performance, simplify test data handling, and support scalability as projects expand. By mastering data structures such as arrays, lists, dictionaries, queues, stacks, and tuples, QA automation engineers can significantly improve the robustness and efficiency of their test scripts. This not only ensures that applications function correctly but also enhances the overall quality of software products. Continuously exploring and practicing these concepts will empower automation professionals to tackle complex testing challenges effectively.
In essence, this code allows you to manage and track user sign-up data and related information using Tuple variables, making it useful for QA Automation testing.
For those interested in data test automation, mastering these data structures can significantly enhance your efficiency and effectiveness in automation tasks.
Keep practicing and exploring to master these powerful tools further with Jignect.
Witness how our meticulous approach and cutting-edge solutions elevated quality and performance to new heights. Begin your journey into the world of software testing excellence. To know more refer to Tools & Technologies & QA Services.
If you would like to learn more about the awesome services we provide, be sure to reach out.
Happy Testing 🙂


